Pratik Daga, Software Engineering Lead at Asana, explains the key steps that businesses should take to successfully implement generative AI-based features.
I cannot recall anything having close to the same impact on the worlds of business and technology as the release of ChatGPT just eight months ago. And here we are, engineers worldwide, stuck in a mad dash to slap some AI on anything and everything. Text and forms used to be good enough for software, but not anymore. Now, with only the barest regard for the potential risks, we’re putting our customers at one end of a new creative partnership with a powerful foundation model API, provided by vendors who still practice move fast and break things.
New data technology partnerships
Generative AI’s prompt-completion APIs allow customers to let the foundation model do the heavy lifting of responding to endless emails or summarising meeting notes. This leaves the customer free to polish the result by tweaking the prompts until the completion text is just right. This new user experience has more in common with creatively applying filters in Photoshop than it does with word processing. What does this mean to observability? Where once we had but to measure the API Response time, now we have to log... what, exactly?
Potential for trouble
Let’s imagine that your company has released an awesome new Generative AI feature, and the customers love it! Weeks go by, and the business dashboards are singing a happy tune. Until one day when the business numbers hit a sour note. The company leadership team calls an all-hands meeting to get some answers. Fortunately, you were forewarned and can now safely say, “I told you this might happen.” You plug in your notebook, throw your observability charts up on the projection screen, and direct everyone’s attention to the data that shows that absolutely nothing has changed in any respect except for two things: the number of prompt-completion API calls per task is decreasing, and the general sentiment of the content is slowly dropping from positive to neutral or negative, depending on the customer segment. The AI feature honeymoon, you say, is over.
Again, you were forewarned and forearmed, so you took the time to lead your business partners through the weeds to help them understand the new reality. The most important difference to highlight is between deterministic and probabilistic software. Before ChatGPT, the software we all worked with was deterministic and always produced the same outputs given the same inputs, following predefined rules. Probabilistic software incorporates randomness and statistical likelihood to generate a range of variables but likely outputs for the same inputs. Deterministic software is easy to verify by QA or business unit. Generative AI is not. To make matters worse, the challenges probability presents are just the tip of the iceberg.
Understanding the issues
For the remainder of the article, the example I’ll use is Gen AI delivered as a black box REST API by a vendor. In preparation for this article, I listed all the standard business, operational, and security risks of incorporating a vendor service into your software product. I then listed the new risks that attend a product like ChatGPT, Bard, or Claude. I was shocked at the result. The category of new technology risks that are not visible by automated means is:
- Hallucination
- Lying
- Alignment
- Unfairness, bias, toxicity
- Catastrophic forgetting
- Model collapse
- Model poisoning
- Drift (data, model, concept)
While the list of visible technology risks is much shorter:
- Semantic drift
- Factual inaccuracy
- Sentiment drift
Perhaps another way to look at these issues is to look at the growth in complexity of a text field’s functional requirements:
- For simple text, the requirement is to validate according to business rules
- For web apps, the requirement is to do a lexical search to detect banned words and injection attacks
- For social media, the requirement is to do sentiment analysis, automated and human moderation
- And for Generative AI, the list of requirements includes:
- Hallucination
- Lying
- Factual accuracy failure
- Model drift
- Data drift
- Concept drift
- Semantic drift.
I was going to say that your best defence against the invisible risks is not migrating to a new LLM version before you have fully tested it, but that was before I read this paper: How is ChatGPT's behaviour changing over time? Three researchers at Stanford University document changes in ChatGPT’s behaviour over time, including its sudden failure to produce correct results for prompts intended to elicit facts about prime numbers, for the same version of GPT-4: “... GPT-4 (March 2023) was very good at identifying prime numbers (accuracy 97.6%), but GPT-4 (June 2023) was very poor on these same questions (accuracy 2.4%).”
They also note the following in the abstract's second sentence: “…when and how these models are updated over time is opaque.” So much for planned updates.
For anyone considering adding OpenAI, three questions must be answered:
- How did this new version make it past OpenAI’s QA?
- If your Gen AI use case needs factual data in the chat completions, can LLMs be trusted?
- How can LLM consumers implement observability and monitoring for the sudden appearance of factually inaccurate completions?
A new kind of observability
Probabilistic software like Generative AI means we can no longer rely on automated QA alone. We also need real-time monitoring of the content of the completion API. Unfortunately, checking every response for accuracy and consistency would be prohibitively expensive and slow.
For you
Be part of something bigger, join BCS, The Chartered Institute for IT.
On top of monitoring the API, we will also need to add observability of the customer’s experience when using the new Gen AI feature, learning to craft better prompts and polishing their prose. As is tradition, they will be our canary in the coal mine, our first indication of collateral damage hiding behind the AI floom.
Consider this example: a call centre message queue suggests responses to customer messages, and a call centre agent modifies the response to suit business rules.
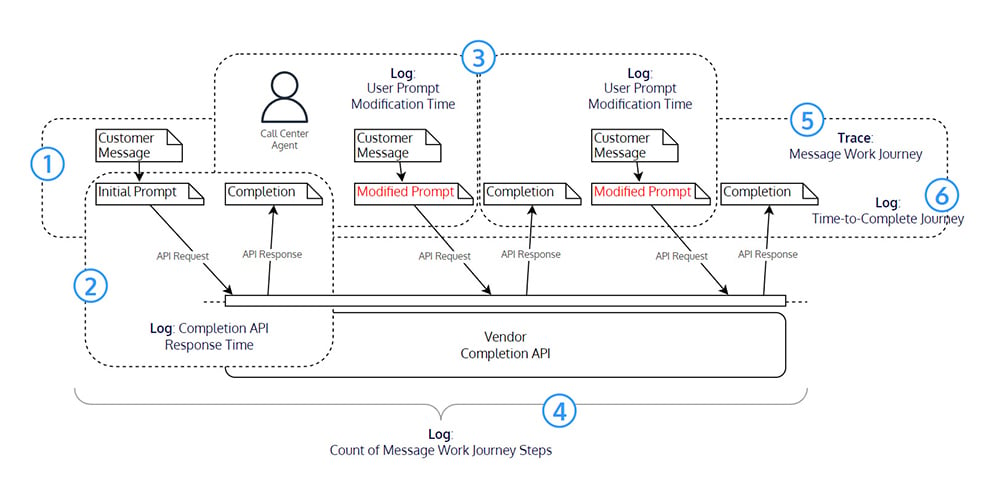
- The call centre message queue pushes a customer’s message to a call centre agent
- The message is sent with an initial prompt to the vendor completion API
- The call centre agent reviews the completion and makes one or more modifications
- When the call centre agent is satisfied, the completion is sent to the customer
- A message's entire journey or lifecycle is traceable
- The total time taken for a call centre agent to complete the journey is recorded.
This provides a high standard of observability to the business, Ops, and Dev teams.
What’s missing is the ability to answer a class of questions we never had to worry about with deterministic software:
| Deterministic | Probabilistic |
|---|---|
| API: Rules-base service | API: Not rules-based. Incorporates randomness and statistical likelihood |
| User of the API can easily test for correctness | Users of the API can only test for ‘consistency within expectations’ |
| Tests metrics are binary: Pass/Fail | Test metrics are comparative, not absolute. |
To answer this new class of questions, we have to look into the ‘Completion’ described in the scenario above.
The solution
Since we can’t reasonably examine every API call, all that is left to us is a kind of continuous QA of the completion’s semantic content. This is easily achieved by creating a text embedding of a completion returned by the API on Monday and comparing it to the completion returned on Tuesday and every day after that.
This observability solution’s ingredients are:
1 set of benchmark phrases, diverse yet representative of the kinds of text prompts the end users will send to the Gen AI API. (handmade)
1 Vector visualisation tool for benchmark dataset creation
1 Sentence transformer language model
1 Gen AI API account
1 Vector database
1 Vector similarity function (cosine similarity provided by the transformer above)
1 SQL database
5 Jupyter notebooks
Then carry out the following:
- Prepare the vector and SQL databases
- Prepare the benchmark dataset
- Create the baseline data: import the benchmark dataset to the vector database and sentence embeddings of the benchmark completions
- Every day or week, send the benchmark dataset records one at a time to the API, calculate the semantic similarity of the baseline completions to the current completions, and store the results in the SQL database
- Query the SQL database to show any change in the semantic similarity of the baseline completions to the subsequent completions.
A note about ingredients
Many vector databases, sentence transformer language models, and vector similarity functions exist. You must explore and experiment to determine the ingredients that yield the best result for your use case. Particular care should be taken when choosing the vector similarity function, as accuracy vs. speed tends to make tradeoffs. You’re not doing a semantic search for this use case, so choose accuracy over speed. Also, note that text embedding vector similarity accuracy tends to decrease for longer text lengths.