





The coronavirus disease (COVID-19) was first identified in Wuhan, China in December 2019. It has since spread to 210 countries and territories, infecting 1,697,356 people and causing 102,667 deaths as of April 11, 2020.
Evolution of COVID-19
Compared to the previous outbreaks of severe acute respiratory syndrome (SARS) and Middle East respiratory syndrome (MERS), COVID-19 has caused more infections and deaths, spreading from an infected person to 2-2.5 people on average. Most countries started reporting infections by the second half of January 2020. The United States reported its first case on January 20, 2020 while England, under the United Kingdom, reported its first cases on January 31, 2020.
Singapore reported its first case on January 23, 2020. In an effort to contain the COVID-19 pandemic in Singapore, multiple interventions have been implemented on both societal and health care system levels and the country shifted rapidly to Disease Outbreak Response System Condition (DORSCON) orange, the second-highest level of alert for disease outbreaks in Singapore, on February 7, 2020, just 15 days after the first case of COVID-19 infection was confirmed. The World Health Organization (WHO) declared this disease as a pandemic on March 11, 2020 and is unable to ascertain the duration of the pandemic.
About the study
For this study, developing an identification and understanding of COVID-19 Information, data was collected from India and the UK for the time periods between February to April 2020. The sampling approach was non-random and self-selected based on the term ‘COVID-19 prevention and cures’.
This specific study was conceived during this period from our viewings of various online social network posts with the data beginning to appear after January 2020, when the USA initially began to report on this topic. We began to create a database where the data was collated manually based on the term ‘COVID-19 - prevention and cures’. The data was acquired from a variety of online resources, including Twitter, Facebook and YouTube - three popular social networks that have proliferated daily life activities. We had to pursue this course of action as the pandemic-related data is still novel and not widely available or understood.
To determine the verification and validity, this obtained data was then checked for accuracy and rigour using websites that confirmed or disputed COVID related data. Sites such as, Snopes, healthfeedback, vishvasnews, altnews, smhoaxslayer, factly, factcheck, webmd, NewsGuard, Alt News, to name a few, were used for confirmation purposes.
Also included in our dataset was the use of misinformation claims used by the previously mentioned fact-checking sites and their successive investigations. These entries included both authentic information (or positive information) as well as misinformation (or negative information) debunked by such sites. To ensure that the data was collated not only from India and to ensure that there was data triangulation in our work, many negative samples included those questioned by authentic medical practitioners in the UK and USA - online news webportals such as, The Guardian, The New York Times, The Huffington Post, BBC News, Washington Times, The Independent, etc.
For data triangulation, we also drew on secondary data drawn from non-government organisations, such as the World Health Organization (WHO), Centers for Disease Control and Prevention (CDC), Ministry of AYUSH Chinese Medicine. This led to a dataset containing a sample size of 143, out of which 82 were false or negative samples (i.e. misinformation) and the remaining 61 being a positive sample (i.e. authentic information) - from sources including Government of India, National Health Commission & State Administration of Traditional Chinese Medicine of the People’s Republic of China.
Examples of misinformation included statements such as ‘children can’t get coronavirus’ and that ‘garlic cures COVID-19’. Here are more examples of three false and three true pieces of information:
False
- Taiwan Experts Provide A Simple Self-Check That We Can Do Every Morning
- Coronavirus: What misinformation has spread in Africa?
- The Great Amritsar – Most Urgent,Very Serious, Important information
True
- WHO: Q&A on coronaviruses (COVID-19)
- Advisory for coronavirus: Homoeopathy for Prevention of Coronavirus Infections. Unani Medicines useful in symptomatic management of coronavirus infection
- Diagnosis and Treatment Protocol for Novel Coronavirus Pneumonia
Social networks at the centre of misinformation
Focusing on the examples of COVID-19 information gathered from websites and online social networks, the results showed Facebook in particular as having the largest amount of misinformation. Twitter was second, followed by YouTube. The posts focused on ‘cures’ such as keeping oneself hydrated; drinking lemon slices in lukewarm water, drinking warm water, gargling, or taking vitamin C or vitamin D.
There were a few posts that mentioned 5G causing COVID-19, dairy products causing COVID-19 or animals such as goats also causing COVID-19. A reason for COVID-19 was also cited as China using COVID-19 as a biological weapon. Therefore, the misinformation content varied, ranging from technology being a cause of COVID-19 to various ways of ‘curing’ COVID-19. The false posts were mostly from March and April 2020.
Finding true information
True information included 10 factual posts from Facebook, including one mentioning Israel having no COVID-19-related deaths (at that time); the nature of COVID-19 and cleaning hands to combat the virus. Other posts were drawn from news websites such as Chinadaily or the World Health Organization (WHO). The true information posts were usually posted in April 2020, when the issue of misinformation became a paramount issue of concern for countries. An apparent difference between the true and false posts were that the true posts contained posts from WHO, as well as other posts.
One constant…
In the false ones, there were no posts from WHO, so the question of authority and power was missing in the false posts. What was also discovered is that with the false posts, there was emphasis on medicines (hydroxychloroquine), the use of warm drinks, hot temperatures, vitamins or root vegetables (ginger). Comparatively, the true posts were based more on scientific facts and details; thereby, not disputed facts. Finally, the UK posts were focused on cures and preventions that were allopathy medicine based, whilst the India posts emphasised Ayurvedic medicine.
Finding the cure
In terms of contributions, we began by searching for other COVID-19 information; misinformation studies that have been conducted on websites and online social networks/social media, as websites related research on COVID-19 cures and preventions are rare. COVID-19 related information studies such as, Li et al examined YouTube videos for usability and reliability of videos. YouTube videos were analysed using the novel COVID-19 Specific Score (CSS), modified DISCERN (mDISCERN) and modified JAMA (mJAMA) scores.
Discovering the results
The Li et al (2020) study highlighted that over 25% of YouTube’s most viewed English language videos contained non-factual or misleading information, reaching over 62million views and nearly 25% of total viewership. There were high proportions of non-factual videos in the entertainment and internet news categories and moderate amounts in consumer and network news categories. In comparison with these sources, professional and government videos demonstrated higher accuracy, usability and quality across all measures but were largely under-represented in the Li et al sample.
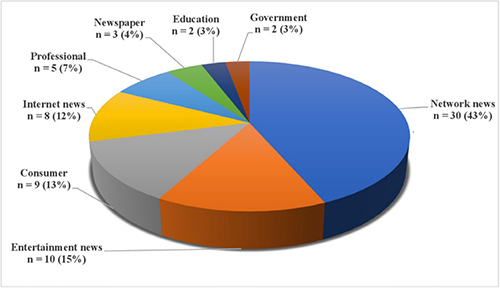
Figure 1: Sectors from which YouTube content was obtained. Source: Li et al (2020)
What were the drivers?
Ahmed et al developed an understanding of the drivers of the 5G COVID-19 conspiracy theory and strategies to deal with such misinformation. The study used a social network analysis and content analysis of Twitter data from a seven day period (Friday, March 27, 2020, to Saturday, April 4, 2020) in which the #5GCoronavirus hashtag was trending on Twitter in the United Kingdom.
Social network analysis identified that the two largest network structures consisted of an isolated group and a broadcast group. The analysis also revealed that there was a lack of an authority figure who was actively combating such misinformation. Content analysis revealed that, of 233 sample tweets, 34.8% (n=81) contained views that 5G and COVID-19 were linked, 32.2% (n=75) denounced the conspiracy theory and 33.0% (n=77) were general tweets not expressing any personal views or opinions. Thus, 65.2% (n=152) of tweets derived from non-conspiracy theory supporters, which suggests that, although the topic attracted high volume, only a handful of users genuinely believed the conspiracy. This paper also shows that fake news websites were the most popular web source shared by users; although, YouTube videos were also shared.
English language fact checking
A third study Brennen et al identified some of the main types, sources and claims of COVID-19 misinformation by combining a systematic content analysis of fact-checked claims about the virus and the pandemic, with social media data indicating the scale and scope of engagement. This led to 225 pieces of misinformation being analysed using a corpus of English language fact checks gathered by First Draft, focusing on content rated false or misleading.
The corpus combined articles to the end of March from fact-checking contributors to two separate networks: the International Fact-Checking Network (IFCN) and Google Fact Checking Tools. The study systematically assessed each fact-checked instance and coded it for the type of misinformation, the source, the specific claims it contained and what seemed to be the motivation behind it.
Furthermore, social media engagement data was gathered for all pieces of content identified and linked to by fact-checkers in the sample to get an indication of the relative reach of and engagement with different false or misleading claims. A majority (88%) of the sample appeared on social media platforms. A small amount also appeared on TV (9%), were published by news outlets (8%), or appeared on other websites (7%).
Contributions of this study
Our study’s contribution lies in it being diverse to other misinformation studies due to its identifying and examining for generic COVID-19 cures and preventions. This was achieved using posts obtained from websites and online social networks.
The total size of the dataset was 143, of which 82 were false or negative samples (i.e. misinformation) and the remaining 61 are positive samples (i.e. authentic information). Further, as shown in ‘Figure 2’, we developed a customised framework for the classification of COVID-19 cures and prevention into true and fake information.
The primary stages in the development of the classification framework are data collection, feature selection (source of the article, e.g. URL: any official health organisation that supported the url source), extraction, development of an AI-based classifier and its validation. We designed a bi-class classifier based on the manually extracted features from the various coronavirus related articles. The strength of our model lies in identifying true or false coronavirus-related information given; that there is the absence of a supporting agency offering such information for a piece of information and text containing investigations that either support or oppose such claims.
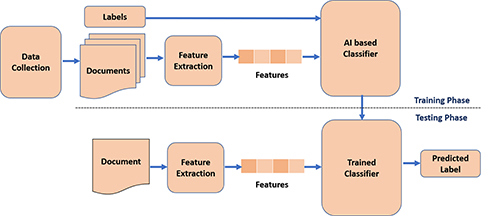
Figure 2: How the data was sorted and classified.
In terms of AI, our model achieved an accuracy of 86.7% with the Decision Tree classifier and an accuracy of 86.67% with the Convolutional Neural Network model. We recognise that the sample size of our study is small, thus we are seeking future directions for this study to acquire a larger database with an aim similar to this study. Our study is also diverse to other COVID-19 related studies because we did not delve into matters associated with usability, being specific to topics, or emphasising and identifying the types and claims of COVID-19-related information.
This study is also our effort to deal with the ‘infodemic’ of medical misinformation that WHO specified presently exists in the context of COVID-19. We intend to increase our dataset considering other dimensions and explore other factors that affect the decision or credibility of a piece of information.
Presently, linguistics features have led to reasonable results for this study, which we intend to advance further by including syntactic as well as semantic features when dealing with text. For instance, for decision making, meta features (e.g. number of URLs in the article, number of links to the article, comments, etc.) and different modalities like images and videos, will allow our model to become a hybrid decision model. We intend to further this study by seeking a larger dataset which could identify that our trained model can identify larger numbers of information. A larger database should also lead to a better understanding of the evolution of misinformation and detect more differences between the health care information in the UK and India.








