





In these days of software-as-a-service, with cloud based database services (such as Amazon Redshift, Microsoft SQL Azure, Google BigQuery et al.) becoming commonplace we face the challenge of how to handle the ETL (extract, transform, load) processing required to perform meaningful analytics against data stored in these database services.
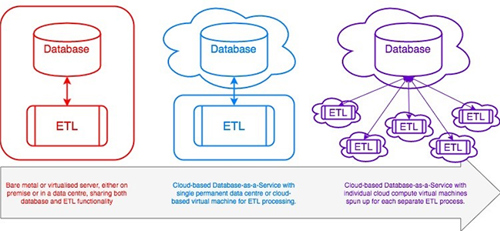
Traditionally you would have invested in a physical, on premise, database server which would provide your database service and would also be the hardware on which you would run your ETL routines. This would be specified and sized to allow capacity not just for your query loads, but also for running your largest, most intense ETL routines.
More recently these physical servers became virtualised and then they were outsourced to data centres, which provided failover and disaster recovery. However, now our databases have become services and now exist in the cloud without the ability to utilise the hardware that provides the service.
All this leaves us with a conundrum, without access to the hardware providing the database service, we have nowhere to run our ETL processes, so...
Where do we run our ETL routines now?
One solution would be for you to create a dedicated ETL virtual machine either hosted in a data centre or hosted by a cloud compute provider such as the aforementioned Amazon, Microsoft, Google et al. However, this suffers from the same problems and constraints as our legacy model of running these routines on our traditional database server, in fact these issues are exacerbated.
That’s not to say that this solution doesn’t work, but because you would be falling back on old established hardware patterns, you would be paying for and maintaining a permanent virtual machine which has to have been provisioned and sized to be able to cope with the largest ETL load. Of course, most of the time this is sitting around idle (as typically ETL routines run on a regular cycle, quite often a daily one) and so you're paying for a permanent resource that you are under utilising.
Perhaps we need to take a new approach and rethink how we deploy, schedule and run our ETL routines. More often than not, these are self-contained packages which perform a set task (moving and/or transforming data from one place to another); one job might be dependent upon another for its input data, but this is a scheduling/orchestration issue rather than a physical connection between the two jobs.
If you follow this approach through then why not package each ETL routine up separately?
You can then spin up a cloud compute instance to undertake this (and only this) task which can then be cleanly disposed of once its task is complete.
This way you only pay for the computing power that we need for the time that we need it; smaller, lighter weight processes can be run on smaller, lower powered virtual machines, hence minimising the cost incurred. Of course another advantage of this approach is that every ETL routine runs in a new clean environment and is isolated from any other tasks; we have no garbage accumulation issues, no interference from rouge tasks, no competition for local resources, all in all a much smoother and more reliable deployment environment.
So, assuming you adopt this approach, that is to develop your ETL processes as standalone components, which will be deployed in isolation from each other, how could you go about this? Should you choose to deploy each ETL process as its own standalone virtual machine or do we try a containerised approach?
Containers?
The development of containers, using a tool such as Docker, is recognised as an agile, lightweight mechanism for continuous deployment, particularly where you have a product or service which needs to be available all the time and which you are continually developing and refining, but does it lend itself to our scenario?
In this instance I don’t believe so, were you to develop a containerised deployment, for example using Docker, you would need to have a Docker server or cluster on which all your containerised ETL processes are run. This would need to be available on a permanent (or at least semi-permanent) basis; effectively moving you back into the scenario where all your ETL is run on a single dedicated server.
This might work if you need a container service for other purposes and if this has enough capacity to handle your ETL processes when they need to run, but this often won’t be the case. When this isn't the case you'll now be provisioning a permanent machine or cluster sized to handle your largest ETL load with the added overhead of your container service; in effect you'll be worse off than before.
Stand-alone ETL machines?
Deploying each ETL process as its own virtual machine might sound like a lot of work, but by using a tool such as Packer, which allows you to quickly and easily build virtual machines for most environments, this isn't such a chore.
Building each separate ETL process as its own virtual machine enables you to provision and size each machine according to its actual hardware requirements, to spin each one up individually as it's needed and for only so long as it takes to complete its work.
As a consequence you only pay for as much computing power as you need and only for as long as you need it. Cloud computing services even monitor your use and recommend changes in the resources such as CPU and memory that you have allocated to each machine in order to further streamline your costs.
The only overhead you require in this scenario is a permanently available, but lightweight, scheduling and orchestration service or server in order to instantiate the virtual machines needed to run the complete ETL process. As this doesn't perform the actual ETL work it won't require very much resource and so will be a minimal on-going overhead.
Code-as-a-service?
So containers have possibilities, but probably, in most traditional ETL scenarios aren't the solution you're looking for; stand-alone code modules deployed as virtualised compute engines seem to offer a good solution. How about code-as-a-service, for example, Amazon's AWS Lambda service?
Can you deploy your ETL directly as code and have it managed and scaled by a service? If not yet, then you probably will be able to in the near future. These services are still developing, so whilst I think you'd cause yourself a lot of hard work developing an ETL processing solution on them at present, it's unlikely to be long before they also demand greater consideration.
Rethinking your architecture
If you are looking to move your data and analytics platform away from physical infrastructure into a cloud environment where infrastructure exists only as code, how can you achieve this?
Firstly you’ll have to rethink your architecture and unlearn past architectural patterns.
Today you can provision your database needs through a cloud database service and you can deploy your ETL as cloud compute instances for which you only incur cost as you use them, but for which you do need to build and store virtual machine instances.
In the near future you’ll probably be able to deploy your ETL code directly to a completely scalable code-as-a-service provider.








