





Giants such as Google, Microsoft, Oracle and Amazon adopted global server load balancing (GSLB) technology some time ago for customer-facing services, but they are now applying the same principles to their internal systems. Nick Williams looks at how GSLB has grown up over the years and explains how the technology is no longer the preserve of the big budget holder.
The principle of load balancing connections across multiple servers in one data centre or multiple data centres has been around for a long time using 'round robin' domain name system (DNS). This technique allows for multiple IP addresses hosting the same service to be registered against a single fully qualified domain name (FQDN) on a nameserver. When a client DNS request is made, the nameserver rotates the order of the server list it responds with, which means clients are directed to different servers. Though this technique distributes load and can deliver a degree of fault tolerance, it does have its drawbacks.
Amongst these is the fact that the issuing nameserver has no knowledge of the health status of a target server or its load-bearing capabilities, which can result in client requests being directed to dead or overloaded servers. In addition, there can be complications around DNS caching, which will cause local DNS servers and clients to keep using the same server IP address until a time to live (TTL) counter has expired. Both of these issues can, however, be managed and as long as the implementer understands and accepts its limitations, round-robin DNS can deliver a modest and cost-effective local or GSLB solution.
Towards the back-end of the 1990s, a number of companies such as Foundry Networks and F5 Networks were bringing to market a range of network appliances specifically designed to address some of the limitations described above. These intelligent load-balancing devices were application-neutral and used simple network techniques to distribute traffic across a group of member servers that were either directly attached to the appliance or available via a switched or routed network. Simply put, the appliance would announce a 'virtual server' IP address to the outside world and client connections to that address would be forwarded on to the member (real) servers using a predefined load-balancing algorithm. The principles are the same as network address translation (NAT), albeit with some intelligence thrown in.
The most significant development was the ability of the appliance to interact with the member servers at the network and application layers, which allowed them to load-balance connections based on the health of a target server and the type of services it was running. For example, it was now possible to check the network reach-ability of a member server using internet control message protocol (ICMP), as well as ensure that its HTTP service was running correctly, before forwarding client connections to it. The risk of forwarding connections to a 'dead' server was no longer an issue, because, if a member server failed its health check, it would be removed from the load-balancing pool and the systems administrator informed that there was a problem.
The level of features offered by this new breed of load-balancing appliances grew extensively and included numerous methods for maintaining session persistence between the client node and the real server, as well as the ability to offload processor-intensive duties such as secure socket layer (SSL) termination. Content verification tools have been introduced to check that a web server is actually serving the correct content and advanced scripting tools now allow an ecommerce process to be checked from end to end before being allowed to service client transactions.
Load balancing, whether done in software or hardware, is now seen as an essential mechanism in delivering better performance and fault tolerance to a wide range of application server environments. High availability (HA) configurations allow pairs of load balancers to be installed in an active / active or active/passive mode, which further extends the protection against the entire platform becoming unavailable because a front-end load balancer has failed.
Solution architects also often implement diverse power feeds, switching and multiple IP transit feeds in an effort to deliver high-availability type services to the ever-increasing community of businesses that depend on their internet presence. The reality is, however, that no matter how much fault tolerance you build into a service, if it is hosted in a single data centre and that data centre suffers from a partial or total outage, then the chances are you will lose service.
We've all heard the stories about generators not kicking in after a mains power failure, or row after row of servers invoking their thermal shutdown protection because the air cooling has failed in a facility. These stories are true and becoming more frequent as DC operators struggle to deal with the challenge of providing sufficient cooling and power to data cabinets deployed with high-density servers.
GSLB serves to address some of the risks associated with hosting all your services in a single location. Both F5 and Foundry Networks have bolted on GSLB technology to their local load-balancing appliances and, although they may differ in how they deliver it, the principle of extending load-balancing across two geographic diverse data centres remains the same.
The most common way of implementing GSLB is by either modifying the DNS response that an existing nameserver gives to a client, or by configuring a GSLB capable load-balancer as the authoritative nameserver for the desired domain. Either way, the request for a load-balanced FQDN such as www.mydomain.com ends up at a GSLB device, which then directs the client to the most appropriate site. It is usual to deploy a GSLB appliance at each site where it is responsible for collecting load, network and persistence metrics for its local site and then exchanging this information with other sites in its GSLB group. This information, coupled with predefined GSLB algorithms and policies, is used in the decision process for where to direct client requests. Typical policy elements that GSLB might use include:
- redirecting client requests to the surviving site when an outage occurs at the primary site;
- directing client requests to the site that is geographically closest to them;
- redirecting clients to another site when traffic or performance thresholds are exceeded at the primary site.
Figure 1 illustrates a typical dual site implementation of GSLB with Site A residing in London and Site B in Paris. Each site has three web servers offering static content for a high-usage web site served by www.mydomain.com. The objective is to manage load by distributing requests across the two sites, manage disaster recovery and ultimately ensure that content is consistently available to client requests.
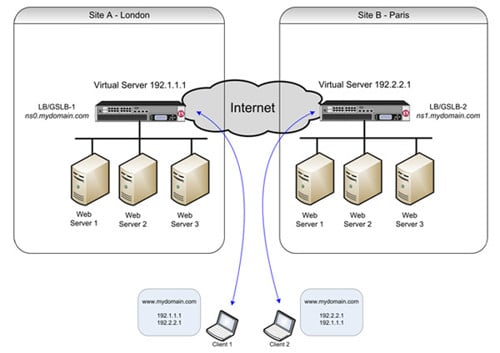 Figure 1. A typical dual site implementation of GSLB
Figure 1. A typical dual site implementation of GSLB
The GSLB devices at each site are configured as authoritative nameservers for the domain www.mydomain.com and they also perform local load-balancing duties for their own three web servers. ICMP and HTTP health checks are configured against the servers and content checking is enabled to ensure that the content being served is genuine and has not been compromised.
As long as both centres and services are healthy, when a client makes a request for www.mydomain.com they are directed to GSLB 1 (ns0.mydomain.com), which responds with an IP list for both data centres. The order of the IP list is rotated, which directs alternate clients to different data centres, thus spreading the traffic load. If a fault occurs that prevents a data centre from being reached, or if any of the preconfigured health checks fail for a service, then the IP address for that site is removed from the DNS IP list and clients are only directed to the healthy site. (Note that in the case of a total site failure, the remaining GSLB appliance services DNS requests for the domain, following DNS protocol.)
Of course, GSLB is still a victim of client-caching and so, even though the authoritative nameservers can dynamically change the IP address associated with a domain, there is no guarantee that the client is going to see this change. This problem is addressed in GSLB by implementing extremely low TTLs, which means the DNS responses normally cache-out within 5-30 seconds.
Unfortunately, there are some applications that continue to ignore these TTLs and for these clients a restart of the browser is normally necessary to connect to a service following a failover. Other challenges include replicating content around GSLB server farms and, where databases are driving content or storing transactions, how to manage database replication. Both these issues are addressed through careful design and a whole raft of middleware applications that are now available in the marketplace.
For many, the internet now delivers their largest revenue stream and, even for mid-sized organisations, every minute of downtime can literally cost thousands. It is no wonder therefore that these organisations invest a significant amount of time and money implementing n+1 architectures into their hosting environments.
The reality, however, is that a catastrophic failure in power, cooling or connectivity at your hosting facility will mean a service outage for you. As GSLB technology becomes more affordable and less of a dark art, more and more organisations are embracing it as a credible mechanism for delivering the high-availability SLAs that they and their customers demand. Let's face it, you wouldn't put all your eggs in one basket, so why would you put all your business critical applications in one data centre?








