





Humans have always desired to better understand the present and predict the future. The algorithms to help achieve this understanding have been around for decades, including even those of artificial intelligence (AI) approaches for enabling computers to reason about things that normally require human intelligence.
However, only in recent years have we accumulated the massive digital data and developed the sufficiently powerful processors needed to put these AI algorithms to work on real human and business problems, with excellent performance and accuracy, on a broad scale.
In this article, we describe some of the fundamental technologies and processes that enable enterprises to put AI to work to transform their businesses. In particular, we explain the concepts of data analytics, data science and machine learning, including deep learning. We also describe data engineering, which is an essential enabler for all of the above. This discussion will provide the basis for understanding deeper dives into machine learning (ML) and deep learning (DL) to follow in subsequent articles. These deeper ML and DL dives will, in turn, provide the foundation for additional articles in this series to demonstrate how these techniques are being applied in real-world enterprise use cases.
Data analytics
In today’s world, all enterprises generate massive amounts of data from diverse sources. Whether it’s from enterprise systems themselves, from social media or other online sources, from smartphones and other client / edge computing devices, or from sensors and instruments comprising the Internet of Things, this data is extremely valuable to organisations that have the tools in place to capitalise on it. The overall toolbox for these tools is called data analytics.
Data analytics is a broad term that refers to the use of various techniques that find meaningful patterns in data. It is a process by which data is converted into insight and foresight. Data analytics tools allow us to describe what happened in the past, draw insights about the present, and - with some techniques - make predictions about the future.
The field of data analytics is not new. It has been used in the business world for decades. Data analytics can be as simple as using statistics to determine the average age or to summarise other demographic characteristics about customers. A linear regression chart in an excel spreadsheet can shed light on sales trends. Yet, as old as it is, the field of data analytics never stands still. It’s continually evolving, as enterprises apply more advanced analytics techniques, such as applications focused on business intelligence and the real-time analysis of data as it streams into the organisation.
The desire to increase understanding about the past, present and future stimulates ongoing advances in the field of data analytics. These advances are necessary for cases where we can’t achieve understanding by simply solving straightforward problems. In the world of business, there are few, if any, hard-and-fast ‘laws of nature’ that will tell you with absolute certainty what is going to happen. To get to this higher-level understanding, enterprises must capture and analyse data using advanced techniques. And this brings us to data science.
Data science
Data science is the cutting edge of data analytics. It’s a process of testing, evaluating and experimenting to create new data analytics techniques and new ways to apply them. As the name implies, data science is, at its core, a practice that follows well-established approaches to scientific investigation. Data scientists are, thus, trying out new algorithms to enable insight and understanding, and measuring the usefulness of those approaches as much as the accuracy of the results. If approaches are deemed generally useful, they become more widely known and contribute to the growing set of data analytics tool.
Thus, while every enterprise should use data analytics in its operations, the need for analytics will increase as companies embrace digital transformation. As they make this transformation, enterprises should constantly push the edge of their analytics capabilities forward. One way to do this is to hire data scientists. Strong enterprise data cultures should include data scientists who continually strive to increase capabilities while working to enable the larger enterprise staff to use mature, proven analytics tools.
Data engineering
While it doesn’t draw the big headlines, data engineering is an essential enabler for data analytics and data science. In simple terms, data engineering makes data useful. It converts structured, unstructured and semi-structured data from different systems and silos into collections of useful, consistent data from which applications and algorithms can extract understanding and value.
Data engineering includes work to clean up datasets - often great amounts of work when dealing with many different data sources and / or data with missing values, errors and even biases. For example, if you’re running analytics on recent homes sales, you’d want to correct or remove any house record with a zero sales price. That erroneous price data would bias your results when included in simple analytics, such as average home price, so the data engineer works to remove it from the dataset, or (better) to correct it if possible. Such data errors can have hidden effects in more sophisticated data analytics that might not be readily apparent in results.
However, they can have severe consequences when using the results.
While you may have heard the term more often in recent years, there is nothing new about data engineering. It’s been around for as long as digital data has been with us. But today, there is an increased need for data engineering as organisations work to merge, curate, reformat and scrub diverse data from an ever-growing range of sources. This process is often required for advanced data analytics applications, including machine learning and deep learning. Data engineers must remove bad data, address gaps and ensure that data does not introduce bias into the results - a topic we’ll explore in a subsequent article.
Artificial intelligence
Artificial intelligence refers to computing systems that have the ability to reason about things and make classifications and decisions that would normally require human intelligence. Common use cases for AI include image recognition and classification, as well as speech recognition and language translation.
While you may hear people talk about AI as if it were new, it’s actually been with us since the 1950s. Since the advent of computers, people have had the notion that machines could be programmed to think the way humans think.
There have been different approaches to AI - to make computers reason as well or better than humans - over the years. One approach that achieved some success a few decades ago was expert systems. These systems follow human-generated, pre-programmed rule sets to carry out tasks independently of humans. For example, we have all experienced expert systems in the form of automated response systems, such as those we are likely to interact with when we call a customer service desk and need to wade through menu options with button presses. (Many of these are now being redeveloped using natural language processing - based on deep learning, described below - to be more flexible and effective, and less frustrating as the natural language processing gets better over time.)
More recently, an approach called machine learning has become a preferred method of realising AI. Even more recently, a subset of machine learning called deep learning has been demonstrated to be extremely effective in certain problem types and workloads - when there is sufficient data to train the models (the ‘learning’ part). Thus, at a broader level, AI encompasses many approaches, with machine learning and deep learning being two approaches that make today’s AI enabled applications possible. 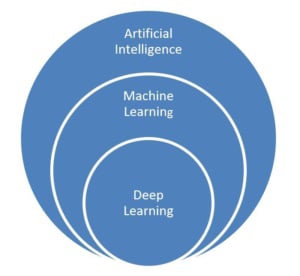
Figure 1. Artificial intelligence is an overarching concept
Machine learning approaches are currently the most used, and most successful, AI approaches in enterprise and consumer applications. Deep learning is a subset of machine learning that is especially powerful for certain workloads like image recognition, natural language processing, sentiment analysis and other uses where there is enough high-quality data to train the models to achieve high accuracy.
Machine learning and deep learning
Machine learning is a sub-field of AI that provides systems with the ability to learn from data and improve over time without being explicitly programmed. Machine learning algorithms use data to generate and refine rules. The computer then decides how to respond based on what it has learned from the data. The key here is that you’re letting the data guide the development of rules.
Machine learning techniques can use diverse data types, including unstructured or semi-structured data, to help derive the understanding that leads to system-generated actions and decisions.
Let’s consider a deliberately simple example. With classical machine learning, you could give a system a set of features common to cats in photos of several types of animals. You could then let the system sort through databases filled with photos of animals and find which combinations of human-supplied features identify all the cats in the mix. In the process, the machine learning system gets better and better as it learns from its experiences with the data.
Deep learning is a type of machine learning built on a deep hierarchy of interconnected ‘neural network’ layers, with the ability to learn key ‘features’ from the data provided to the system. The deep learning technique takes massive amounts of data and determines the common rules and features associated with the data. As with classical machine learning, data guides the training of the deep learning model.
Let’s expand on our cat example. If you give a deep learning system enough images of cats, the system can - all on its own - determine the features that make a cat a cat, such as characteristics related to the eyes, ears, whiskers and tail. This ability to learn goes beyond that of classical machine learning, because in this case you don’t have to tell the system what features to look for. It figures that out on its own.
So why does this matter?
We all benefit in countless ways from AI, which is now virtually everywhere in our lives. Have you used Google today to search the Internet? You’ve benefited from AI. Have you used a credit card lately? You’ve benefited from AI programs that validate user identities and stop potentially fraudulent transactions. Have you encountered online stores that make personalised suggestions based on the products you’re looking at? That’s AI at work.
AI changes the ground rules for decision-making in the enterprise. Machine learning and deep learning techniques, for example, allow executives to weave in data from many sources - such as social media sites, customer information systems and e-commerce sites - to make better predictions about the products that are likely to sell in the future and the people who are likely to buy them. Decision makers can then tailor their product-development and sales and marketing strategies accordingly.
It’s important to emphasise that AI is no longer a niche application. Across a wide range of industries, enterprises are putting AI to work to build stronger customer relationships, make smarter business decisions, improve the efficiency of processes, and bring better products and services to market, some of which may include AI.
The use cases for AI are virtually unlimited, spanning from healthcare and financial services to manufacturing and national defence. If you have massive amounts of data, AI can help you find and understand the patterns contained within it.
Image credit: Joshua Sortino








